生成AIを用いたシステムのリスク低減と信頼性向上のために
生成AI品質マネジメントガイドライン第1版を発行
ポイント
・ 生成AIを対象とした品質マネジメントのガイドラインを開発し、公開文書として発行
・ 大規模言語モデル(LLM)を部品として利用して、生成AIシステムを開発・運用する企業に向けて、品質を実現するために行うべき事項を体系的に提示
・ LLMを利用する生成AIシステムが開発者および利用者の期待された通りに機能、高い品質を維持することに貢献

概 要
国立研究開発法人 産業技術総合研究所(以下「産総研」という)インテリジェントプラットフォーム研究部門、サイバーフィジカルセキュリティ研究部門、および人工知能研究センターは、生成AIを対象とした品質マネジメントのガイドラインを開発し、公開文書として発行しました。
製品やサービスにおける品質とは、製品やサービスの提供する機能が事業者や開発者および利用者の期待した通りに機能することを指します。これを実現、維持するための体系的な方法や仕組みを品質マネジメントと呼び、事業者や開発者には一定の品質を保ちながら顧客や社会の要求に応え続けることが求められます。近年、対話型AIや文章生成AIなど、大規模言語モデル(LLM)を用いた生成AIは急速に性能を向上させており、企業や一般の人の間でも活用が広がっています。しかし、LLMを使用した生成AIには、誤った情報の提示や差別的な判断などにより、利用者に被害を与える恐れがあることから、適切な品質マネジメント手法の整備が求められていました。
今回、生成AIの品質マネジメントの考え方を示すガイドラインを開発し、公開文書として発行しました。このガイドラインは、他社が開発しオンラインサービスやオープンソースソフトウェアとして提供されるLLMを部品として利用し、生成AIシステムを開発、運用する企業を主な対象としています。利用者に対して一定の品質を備えたシステムを提供するため、開発・運用者が行うべき事項を体系的に示しています。
なお、このガイドラインの詳細は、2025年5月27日に2025年度人工知能学会全国大会のチュートリアル講演で発表されます。
下線部は【用語解説】参照
開発の社会的背景
2022年後半以降、画像生成AIや大規模言語モデルを基盤とするチャットボットが広く社会に提供され、その想定を超える高い性能によって社会に大きな衝撃を与えました。その後もこれらの生成AIは急速に性能の向上を続けており、企業や一般生活者の間でも活用の動きが広がっています。生成AIは、従来型ソフトウェアや生成AI登場以前に主流であった識別・予測型のAIとは異なる手法で開発されており、その特性も大きく異なるため、従来の品質マネジメント手法をそのまま適用することはできません。品質マネジメントの手法が明らかでないまま生成AIを活用しようとすると、1)十分な品質が実現できず、利用者やその周辺に居合わせた人などに被害が生じる、2)生成AI利用システムの開発者・運用者と利用者の間で、品質に関する合理的な契約条件が決められない、3)高い品質が実現できても、そのことを利用者や社会にアピールできない、といった問題が生じます。さらに、生成AIの高い能力と急速な進化を受けて、安全性に関する懸念が国際的に広がり、2023年末から2024年にかけては、日本を含む各国でAIセーフティ・インスティテュート等の監督機関が設立され、国際連携体制のもとで生成AIの安全性確保に向けた取り組みが進められています。安全性は品質の主要要素の一つであり、生成AIの品質マネジメント手法の一環として、安全性確保の手法へのニーズが高まっています。
LLMを用いた生成AIを含む、AIの事業者向けのガイドラインとしては、これまでに、総務省と経済産業省からは「AI事業者ガイドライン」、AIセーフティ・インスティテュートからは「AIセーフティに関する評価観点ガイド」「AIセーフティに関するレッドチーミング手法ガイド」などが発行されてきました。しかし、このうち前2件は、生成AIの事業者が組織としての観点から取り組むべき事項に重点をおいており、また最後の1件は外部からの攻撃に対する生成AIの備えの評価に焦点をあてたものであって、いずれも生成AIの開発や運用の現場での品質マネジメント手法の全体を示すものではありませんでした。
研究の経緯
産総研は、以前にも機械学習を用いたAIシステムの品質管理を体系的にまとめた「機械学習品質マネジメントガイドライン」を公開しています(2020年6月30日 産総研プレス発表)。このガイドラインは、識別・予測型のAIシステムを対象とした品質マネジメント手法を示したもので、その後の第4版までの改訂版が示す手法は生成AIにはそのまま適用することができません。そこで、2023年度から、産総研は企業・大学などの有識者委員と共に構成した「機械学習品質マネジメント検討委員会」において、生成AIの品質マネジメントについて検討を進めてきました。
なお、本研究開発は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の委託事業「人と共に進化する次世代人工知能に関する技術開発事業/実世界で信頼できるAIの評価・管理手法の確立/機械学習システムの品質評価指標・測定テストベッドの研究開発(2020~2023年度)」による支援を受けています。
研究の内容
【品質マネジメントの対象】
今回発行した生成AI向け品質マネジメントガイドライン(以下「本書」という)が対象とするのは、主としてLLMなどの汎用基盤モデルを部品として用い、ある想定用途のために設計、開発されるLLM利用AIシステムです。このシステムを実現するアーキテクチャの前提となる情報の流れを図1に示します。

ここでは機械学習によって開発されるLLMの品質に加えて、LLMと共にLLM利用AIシステムを構成するコンポーネントである、機械学習以前の手法で開発される従来型ソフトウェアの品質の両方を扱うことになります。また本書では、LLMはLLM利用AIシステムの開発者が外部から調達する再利用部品であって、その開発や品質の実現には直接関与できないと想定しています。この想定は、現在の最先端LLMの開発には大量の資源と資金の投入が必要であり、世界でもそれを行える組織が数少ないことから、本書を手に取る読者の大部分に当てはまると考えられます。そこで本書が提示する手法は、主に従来型ソフトウェアであるコンポーネントを対象に、従来型ソフトウェア向け品質マネジメント手法で従来型ソフトウェア向け品質特性を実現することにより、LLMの品質の不足があれば補って、LLM利用AIシステムの品質を実現するものです。
【対象システムの構成】
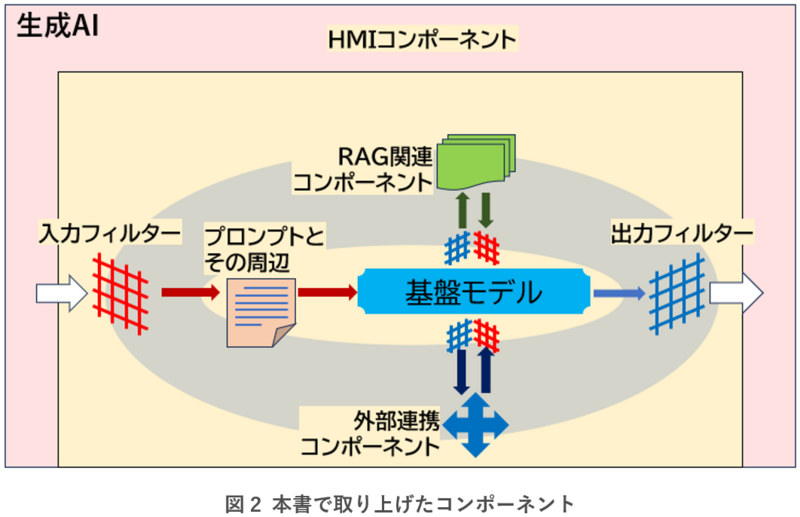
本書では主なコンポーネントとして、基盤モデル以外に、プロンプトとその周辺、RAG関連コンポーネント、外部連携コンポーネント、入力フィルター、出力フィルター、そしてHMIコンポーネントを取り上げます(図2)。
【本書が提示した品質マネジメントの流れ】
LLM利用AIシステムの品質マネジメントの基本的な流れは以下の通りです。
1)LLM利用AIシステムの想定用途からその品質要件を導出する。
2)そこから各コンポーネントに対する品質要件を導出する。
3)各コンポーネントに品質要件を満たすための管理策を行う。
このため、本書では前述のLLM利用AIシステムを構成するコンポーネントごとに、しばしば要件となる品質特性を示し、それらを実現するための管理策を述べています。
【本書が提示した品質特性の一覧】
本書はLLM利用AIシステムが備えるべき品質特性の一覧を示しました。国際標準ISO/IEC25000シリーズに定められたソフトウェア品質体系 SQuaRE が掲げるものを元にしています。ただし、生成AIの技術的な特徴や社会的要請を考慮して、いくつか品質特性の名称を変更し、また独自の品質副特性を追加しています。本書が取り上げた品質特性と品質副特性の一覧を図3に示します。これらは品質観点のカタログであり、全てのシステムで必ずこの全てを満たすことを求めるものではありません。

図3の「コンポーネント品質」はLLM利用AIシステムが全体として、またその各コンポーネントがそれぞれに備える品質です。一方「データ品質」はLLM利用AIシステムとさまざまな形で関わるデータが備える品質を指しています。主なものに、入力プロンプトや、RAGに用いられる外部データがあります。
今後の予定
AIの発展はペースが速く、冒頭に示したアーキテクチャに収まらない複雑さを持つLLM利用AIシステムが既に現れています。今後、それらを対象とできるようガイドラインを速いペースで拡充更新していく予定です。
今回発行した文書の詳細
生成AI品質マネジメントガイドライン 第1版
・ インテリジェントプラットフォーム研究部門 テクニカルレポート IPRI-TR-2025-01
・ サイバーフィジカルセキュリティ研究部門 テクニカルレポート CPSEC-TR-2025001
・ 人工知能研究センター テクニカルレポート
URL: https://www.digiarc.aist.go.jp/publication/aiqm/
用語解説
生成AI
テキストや画像などの、さまざまな内容を表現しうる形式のデータを新たに生成して出力するAI。多くの場合、入力としてもテキストや画像を受け取り、そこに表現された内容を踏まえた処理を行う。
大規模言語モデル(LLM)
機械学習の手法を用いて、大量の多様な自然言語やプログラミング言語で書かれたテキストを訓練データとして用い、それらのテキスト中の語句がどのような連なりとなって現れやすいか、を統計的に学習させたモデルのうち、パラメータ(モデル内の演算に用いる係数)数でみて大規模(数十億以上)なものをいう。学習結果に基づいて、テキスト断片から、その周辺(断片中の欠落箇所や、断片の続きなど)にどのような語句が現れるかを予測させることができる。繰り返し続きを予測させることにより、一連の語句としてテキストを生成させることができる。
プロンプト
大規模言語モデルを用いた生成AIに、入力として与えるテキストであって、一般に、生成AIに行わせたい処理を指定するために用いられる。生成AI中の大規模言語モデルにプロンプトを入力として与え、その続きとしてどのような語句が現れるかを予測させることで出力を生成すると、その結果得られる出力テキストが、プロンプトが表す指示に応じた処理を行った結果を表すものになっていることが多いため、プロンプトが生成AIへの指示手段として使われる。
RAG (Retrieval-Augmented Generation)
主に情報検索に用いる生成AIの実現手法の一つであって、訓練済みの大規模言語モデルが内部に保有する知識に加え、別の情報検索手段で得た検索結果を用いて出力を生成させる方式。一般に大規模言語モデルの訓練にはある時点までの公開情報が使われるため、そのように訓練された大規模言語モデルはその時点以降の情報や未公開情報についての知識を持たない。そこで、RAG方式の生成AIでは、最新情報や秘匿性の高い情報を含む出力を生成させるために、検索要求が与えられた時点でWeb検索を行った結果や、秘密情報を保持する組織内データベースで検索した結果を入力として大規模言語モデルに与える。
外部連携コンポーネント
生成AIの構成要素の一つであって、生成AIが、生成AIの外部にあるシステムの利用や操作を行えるようにする。生成AIの中で用いられる大規模言語モデルの出力に基づいて、インターネットで情報検索を行ったり、インターネット上のサービスを利用したり、ネットワークに接続されたセンサーなどから値を取得したり、ネットワークに接続された機器を操作したりする。外から取得した値は、多くの場合、再度大規模言語モデルに入力として与える。
HMI(Human Machine Interface)コンポーネント
生成AIの構成要素の一つであって、利用者と生成AIのやり取りを仲介する。生成AI以前のソフトウェアシステムにあるものと実現技術としては変わらない。
プレスリリースURL
https://www.aist.go.jp/aist_j/press_release/pr2025/pr20250526/pr20250526.html
本プレスリリースは発表元が入力した原稿をそのまま掲載しております。また、プレスリリースへのお問い合わせは発表元に直接お願いいたします。
プレスリリース添付画像
このプレスリリースには、報道機関向けの情報があります。
プレス会員登録を行うと、広報担当者の連絡先や、イベント・記者会見の情報など、報道機関だけに公開する情報が閲覧できるようになります。
このプレスリリースを配信した企業・団体
- 名称 国立研究開発法人産業技術総合研究所
- 所在地 茨城県
- 業種 政府・官公庁
- URL https://www.aist.go.jp/

過去に配信したプレスリリース
産総研、製造AX拠点を始動
7/2 14:23

“松やに”から黒鉛製造
7/1 18:00
次世代XRコンテンツ産業を規格が後押し
6/29 14:00
「棄てる」廃水処理から「活かす」廃水処理へ
6/24 14:00
運動をすると認知課題中の脳活動が変化する
6/11 14:00
瀬戸内海燧灘(ひうちなだ)において海底活断層の分布を明らかに
5/29 14:00
麹菌に有用物質の“設計図”を素早く読み込ませる方法
5/28 14:00
標準的な製法×新組成設計で、より硬くて変形しにくいガラスに
5/27 14:00
「1つの物体を見るAI」から「複数物体を見比べるAI」へ
5/25 14:00
遺伝子制御に関わる液滴形成のメカニズムに新知見
5/20 14:00
化粧品などの原料のクリーンな触媒合成プロセス
5/18 14:00
共生システムを逆手に取る“トロイの木馬”型微生物は新しい生物農薬候補!?
5/14 14:00












